第11章 限制资源
现在,编译器已经准备好为每条指令分配机器资源(例如寄存器、条件码等)。有若干种可用的资源分配算法,各自擅长处理特定类型的问题。当可用的物理寄存器比所需的物理寄存器数目大得多时,每种寄存器分配算法都表现良好。反之,则每种算法都表现糟糕。
这里给出的算法是多种分配算法的结合,尝试吸收它们各自的长处。它的组织结构是一个算法序列,每个子算法做一部分分配工作。先前以这种方式组织的算法受到phase次序问题的困扰:分配一个临时寄存器集,导致分配其它寄存器集变得更困难。编译器通过限制资源来缓减这个问题。
因此,第一件必须做的事情是减少所需寄存器的数目。在寄存器分配phase和指令调度phase之前做这件事情,之后它们就可以假设存在充足的可用物理寄存器。如图11.1所示,按照下面的次序执行这些功能:
限制资源phase竭尽所能减少对机器资源的需求,同时不减小程序执行的速率。它做如下工作:
执行窥孔优化,生成确定的目标指令序列。
执行寄存器合并(coalesce)和寄存器重命名(rename),尽可能消除复制操作,将流图中多个独立的部分用到的每个临时变量替换为不同的临时变量。
减小寄存器压力,在程序的每个点限制所需寄存器的数目,以匹配可用物理寄存器的数目。
指令调度phase重新组织目标指令,以减少执行流图所需的机器时钟周期数。与此同时,避免寄存器压力增加到超出可用寄存器集。
寄存器分配phase为临时变量指派物理寄存器。这是分三步做到的。
首先,为跨block活跃的(全局)临时变量指派寄存器。
在一个block内,为可以和全局临时变量共享寄存器的临时变量指派寄存器。
在一个block内,为活跃且未分配寄存器的临时变量指派寄存器。
再次执行指令调度phase,当且仅当寄存器分配器插入了load和store操作。
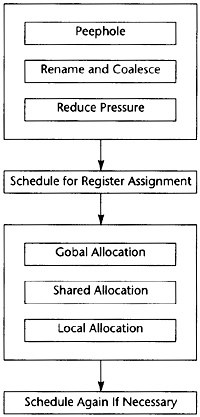
图11.1 Back-End Structure
寄存器分配phase必须高效地利用机器资源。这意味着使用尽量少的寄存器。当寄存器不够用的时候,寄存器分配器插入尽量少的load和store操作。使用最少的寄存器并且插入最少的load和store操作是不切实际的,因为这是一个NP完全问题。作为替代,我们会采用启发式方法尽可能地做好工作。
11.1 限制资源的设计
限制资源phase执行四个动作来减少指令数目和所用的寄存器。它们被分组为两个单独的子phase。首先,执行窥孔优化、寄存器重命名(rename)、寄存器合并(coalesc)。然后,减小所需的寄存器数目(减小寄存器压力),这样在流图的任意点,所需的寄存器不多于机器上可用的寄存器。
如上面提到的那样,本编译器将窥孔优化、寄存器重命名、寄存器合并结合为一个单一的算法。为什么?如果单独实现它们,算法就需要占用大量空间和时间。考虑每个部分:
寄存器重命名涉及将单一临时变量分解为多个临时变量,假如它在流图的多个部分被独立地使用。这要求了解一个临时变量的哪些求值可能被使用。流图的静态单赋值(SSA)形式可以提供此信息。
寄存器合并利用称为冲突图(conflict graph)的数据结构删除寄存器到寄存器的复制。这个冲突图大概是编译器中最大的数据结构。我们观察到,很多重命名可以在流图的静态单赋值形式上进行,而不需要冲突图。只要为小部分临时变量构建冲突图,从而减小它的尺寸。当编译器可以查看每条指令的操作数的定义时,窥孔优化表现最好。静态单赋值形式给我们提供了此信息,因此可以在此时执行窥孔优化。肯定地,要在指令调度之前执行它。
作为一个清理phase,必须删除死代码。再次地,这个算法在流图的静态单赋值形式上执行。
由于这些算法都在静态单赋值形式上运行,它们可以相继执行;但是,它们也可以被结合。在寄存器合并删除寄存器复制的时候,可以同时执行窥孔优化。不久我们会看到,寄存器重命名和寄存器合并可以结合为一个算法,它为了改造正常的流图而计算临时变量的一个划分。
这些基于静态单赋值形式的算法执行之后,算法处理正常的流图和循环结构,插入load和store操作,以减少所需的寄存器数目,匹配目标机器上可用的寄存器。如此,限制资源的主要过程具有如图11.2的形式。
如果流图中不存在非正常边,这些算法可以进一步结合。1 可以同时做窥孔优化、局部合并(coalesce)、构建静态单赋值形式。由于编译器必须避免非正常边的复制操作,必须在执行合并或窥孔优化之前找出这些边和相应的ϕ节点。可以在构建静态单赋值形式期间找出它们;但是,简单起见,我们单独描述它。
- 1
现在,你应该明白了非正常边是编译器编写者存在的根源。

图11.2 LIMIT Main Procedure

图11.3 Effect of Abnormal Edges
必须删除所有非正常边上由phi节点导致的复制。因此,对于这些phi节点中的临时变量,什么也做不了。不改变临时变量求值或使用的点就可以做到。实际上,使用可以被删除,但不能被增加。为了找出这些临时变量,执行图11.3中的算法,它计算两个集合:Occurs_In_Abnormal_ϕ_node,这是这些边所包含的所有临时变量的集合;Pairs_In_AbnormaL_ϕ_node,这是临时变量对的集合,如果编译器不仔细就可能导致它们之间的复制。这个算法简单地查看所有包含任何ϕ节点的block,检查它和每个前驱block之间的边是否为非正常边。如果是的话,就扫描ϕ节点的每个临时变量,将它们添加到这些集合。
11.2 窥孔优化和局部合并
窥孔优化是一种具有机器无关形式的目标机器相关的优化(见图11.4)。不论一个优化编译器如何优秀,对生成的代码执行简单的模式匹配,都有改进的机会:
一个对X的load可能跟着一个对X的store。编译器已经试着消除它们;但是,存在phase次序问题会限制这样的尝试。一个load操作所使用的地址可能是一个临时变量和一个常量的和。在目标机器上,如果这个常量是小的,就可以把它合并到LOAD指令的(地址)偏移中。STORE指令也是如此。
目标机器可能有专用的指令,例如Alpha处理器有S4ADDQ指令。这条指令对一个操作数乘以4,再加第二个操作数。它比乘法指令快,因为一个操作数的位被直接位移后写入目标寄存器。
局部寄存器合并在消除复制指令的时候,让使用其目标操作数的指令改为使用其源操作数,这是一种机器无关形式的窥孔优化。
编译器可以逐条扫描指令,象征性地执行它们,记住尽可能多的信息。当一个常量是0的时候,和这个常量的逻辑AND产生结果0,各个位都是。如果后面的指令尝试修改或查询这些位,编译器就可以改变指令序列来生成更好的代码。

图11.4 Driver for Peephole Optimization
正常来说,窥孔优化按照执行顺序逐条扫描每个block中的指令。本编译器按照流图的支配者线路访问每个block和其中的指令。这意味着每个操作数在其它指令使用它们之前已经被求值。当然,对于ϕ节点是不成立的。对这种情况,编译器必须作最坏的假设:它不知道临时变量的值。对于其它临时变量,编译器记录如下信息:
如果临时变量容纳一个常量值,就记录这个常量值。
如果临时变量不是一个常量值,编译器知道这个临时变量某些位的信息吗?它是正数吗?已知某些位是0或者1吗?
编译器包含一系列在指令流中识别模式的函数:每种指令类型有一个函数。这些函数识别所有以特定指令结尾的模式,为生成更好的代码序列执行所需的转换。它还记录每个临时变量的信息,它们是那种类型指令的目标。如果指令序列改变了,就重新从转换后的序列的第一条指令开始模式匹配。因此,相同的指令可能应用多个模式。
尽管窥孔优化从第一条被转换的指令重新开始扫描使得它能够识别多个模式,有些模式还是不能被识别。重复整个窥孔优化phase,直到没有模式被匹配。对于每个临时变量,上次迭代收集的信息还是有效的。ϕ节点可以利用这些信息在后续迭代中获得更好的信息;然而,不应该仅仅为ϕ节点获得更好的信息而重复整个窥孔优化phase,从中并不能获得足够的信息。
必须避免这样的转换:在Occurs_In_Abnormal_ϕ_node中增加一个临时变量的使用,或者移动这样的临时变量被求值的点。这样一来,编译器就保证后面不会在非正常边上生成复制操作。
图11.5中的算法描述了处理一个block的过程。在一个block中,按照执行的顺序去操作。首先,处理ϕ节点。只有少量转换可能消除ϕ节点;但是,可以从已知的关于操作数的信息获得关于结果的值的信息。

图11.5 Peephole Optimization of a Block
处理了ϕ节点之后,编译器模拟block的执行。在这个过程中,对于列表中的每条指令,调用窥孔优化函数。这个函数会执行任意转换。如果一个转换发生了,就返回值真。下面是窥孔优化的诀窍。如果没有发生转换,编译器会继续处理下一条指令。如果发生了转换,编译器会再次处理被转换的指令,现在这条指令可能不同于原始的指令。必须小心从事,避免跳过一条指令,试图再次处理删除的指令,或者发生通常的崩溃。
处理了这个block之后,继续遍历支配者树,处理支配者树中这个block的子节点。
这里,我们不会描述所有的函数,因为它们的数目和模式取决于目标机器。我们只描述对ϕ节点、复制指令、和整数乘法的处理。读者可以推演针对所有机器的结构。
为任意指令创建函数的时候,首先考虑可以应用的转换。对于ϕ节点,当它具有T0 = ϕ(T1, …, Tm)的形式时,下面的转换是可能的:
如果T1到Tm都是相同的临时变量,这个ϕ节点可以被改写为单个复制操作,T0 = T1。如果所有这些临时变量都不涉及非正常边,就可以删除这个复制。
如果T1到Tm除了一个之外都是相同的临时变量,而那个临时变量和T0相同,那么这个ϕ节点也可以被改写为一个复制操作,并且可能被删除。
因此,处理ϕ节点,首先识别以上两种可能的情况,并作转换。然后,找出操作数共有的特征,把这些特征赋予目标操作数(见图11.6)。
作为正常指令的一个例子,考虑整数乘法指令。窥孔优化怎么处理它?如果它是和一个常量的乘法,它已经被转为位移和加法操作。有必要再次检查一些简单的案例,以防万一它们被漏过或者产生于替换之后。2 图11.7给出了这个函数的片段。注意,这里并没有考虑专用指令,例如Alpha的S4ADDQ。整数加法函数会考虑它,因为它是最后的操作。
- 2
似乎总是发生这样的案例。编译器是精心设计的,使得特定指令的所有实例在编译器中的一个单一的位置被转换;但是,后面的转换可能生成同样的案例。因此,如果代价不高的话,应该去检查这样的案例没有发生。
这里,另一类要考虑的指令是i2i,流图中的整数复制操作。这里只有一种转换。如果源和目标没有涉及非正常边,使用目标临时变量的地方都可以替换为源临时变量,完全消除前者。图11.8对此作了解释。这个函数检查临时变量是否出现在非正常边上;如果不是,就修改所有使用目标临时变量的指令。
在为窥孔优化作扫描时,编译器预先计算出现在复制操作或ϕ节点中的临时变量的集合。之后只为这些临时变量计算冲突图,减少图的尺寸,提高编译速度。集合Occurs_in_Copy存放出现在复制操作或ϕ节点中的临时变量。注意,窥孔优化的每个pass会重新计算这个集合,因为对复制的处理可能会改变出现在复制操作中的临时变量的集合(图11.8)。

图11.6 Peephole Optimizing ϕ-nodes

图11.7 Peephole Optimization for Integer Multiplication

图11.8 Peephole Optimizing Copy Operations
11.3 计算冲突图
寄存器重命名和寄存器合并算法需要一个称为冲突图(conflict graph)的数据结构。3 它表示两个临时变量在流图中一些共同的点具有不同的值。
- 3
通常这个数据结构称为interference graph,重用指令调度期间所构建的数据结构的名字。于是,我选择了卡内基梅隆大学的PQCC项目(Leverett et al. 1979)所采用的名字。
定义
冲突图:给定一个临时变量的集合R,R的冲突图是由节点和边构成的无向图,其节点是R中的临时变量,在临时变量T1, T2 ∈ R之间连一条边,如果流图中存在任意的点p满足下面的条件:
T1和T2可能具有不同的值。
T1和T2在点p同时活跃。这意味着,有一条从对T1的求值到使用的路径包含点p,并且有一条从对T2的求值到使用的路径包含点p。注意,如果其中一个临时变量未初始化,就不需要边。
怎么表示这个数据结构?文献上描述了两种表示方式,本编译器将它们合而为一。鉴于临时变量表示为小的整数,将冲突矩阵表示为一个对称的位矩阵,其中C[i,j]为真,当且仅当临时变量Ti和Tj冲突。这使得访问矩阵检查一个冲突非常快;但是,找出和一个临时变量冲突的所有临时变量比较慢。作为替代,一个冲突图可以这样表示,每个临时变量有一个列表,记录所有和它冲突的邻居临时变量。这使得找出和一个临时变量冲突的临时变量容易了;但是,查明一个特定冲突的存在是费时的。
不幸的是,算法必须执行这两种检查,因为在图的构建期间,它需要检查冲突的存在,而之后它需要知道和一个特定临时变量冲突的临时变量。有些冲突图的实现首先创建位矩阵表示,然后将它翻译为邻居列表。这种转换消耗大量时间。其它的实现同时持有两种数据结构,针对特定的操作,哪种数据结构用起来更有效率就用哪种。这让编译器消耗更多内存。
我们的编译器以两种方式优化冲突图的构建。首先,只为编译器预先确定的临时变量的一个子集构建冲突图。保持小的临时变量集合,就节省了时间和空间。其次,编译器将冲突图实现为一个结合的哈希表和表示冲突邻居的列表。哈希表和图表示共享数据结构,避免额外的内存消耗。
11.3.1 冲突矩阵的表示
本编译器结合了两种表示方式,使用一个哈希表和一个表示无向图的链表。为此,在表中将每条边表示为一个条目。三个不同的链表持有这个条目:
哈希表表示为一个链接的哈希表,因此条目中有一个字段,称为hashnext,存储指向哈希表的这个链中的下一个条目的指针。
小编号临时变量的邻居保存在一个列表中。在冲突邻居列表中,针对小编号节点,字段smallnext代表指向下一个邻居的指针。
相应地,大编号临时变量的邻居保存在一个列表中。在冲突邻居列表中,针对大编号节点,字段largenext代表指向下一个邻居的指针。
对于冲突图来说,不存在值表示和自己冲突的临时变量;因此,一条边连接着严格的小编号临时变量和严格的大编号临时变量。
在条目中还有两个针对边的字段:
字段smaller记录小编号临时变量的数目。
字段larger记录大编号临时变量的数目。
注意,边不存储数据。对算法来说,边的存在是重要的事情。于是,边的数据结构的样子看起来如图11.9所示。
为了检查特定冲突的存在,编译器使用一个链接的哈希表,ConflictHash,它的尺寸大约是HASHSIZE,它可以是2的幂,因为用了简单的哈希函数。设Ti是由整数i表示的临时变量,相应地,设Tj是由整数j表示的临时变量。由于我们对临时变量的频率和相互关系一无所知,哈希函数线性化相应对称位矩阵中的条目,并除以表的尺寸。换句话说,哈希函数生成一个索引,去索引哈希表中的一个链表。当然,根据hashnext向下扫描这个链表,直到找到匹配的smaller和larger,表明找到了一条边。
Conflict(Ti, Tj) =
(if i < j then
j(j - 1)/2 + i
else
i(i - 1)/2 + j) mod HASHSIZE

图11.9 Structure of a Conflict Entry

图11.10 Schema for Referencing Neighbors of Ti
在插入边的时候,新的边被添加到链表的头部,因为局部性表明,一旦发生了一次插入,很可能很快会尝试相同的插入。
其它操作是找到一个临时变量所有的邻居。设Ti是整数i相应的临时变量。利用一个类似图11.10的算法,向下扫描和Ti冲突的临时变量的列表。
编译器还会记录一个临时变量的邻居数目。为此,给临时变量增加一个属性,称为NumNeighbors,它初始化为0,并且每次添加一个冲突就加1。
11.3.2 构建冲突图
定义给出了计算冲突图的基本技术。考虑流图中的每个点。如果两个临时变量在某个点是活跃的,并且不知道它们是否具有相同的值,就在它们之间生成一条边。这意味着,编译器需要知道每个点活跃的临时变量的集合。在活跃或死亡分析之后,编译器只知道在每个block末尾活跃的临时变量。找出block内部任意点的活跃临时变量的方法是,向后扫描block,应用活跃变量定义来更新其集合,如下概述的那样:
向后扫描指令,首先将作为当前指令的目标的临时变量标记为死亡。
将作为操作数的临时变量标记为活跃。
对于在一个特定的点活跃的(T1, T2)对,在冲突图中创建一条连接T1和T2的边。
这个方法是低效的,因为通常两个临时变量在大量的点是活跃的。算法会尝试在每个这样的点插入一个冲突。当然,编译器会发现这个冲突已经存在了,不会插入它。但是,尝试这些无用的插入会消耗大量时间。作为替代,我们会利用Chaitin(1981)所作的观察去减少工作量。
观察(Observation)
考虑从入口点到T1和T2活跃的点p的任意路径。下面的条件之一是成立的:
在路径上对T2求值的某条指令处T1是活跃的。
在路径上对T1求值的某条指令处T2是活跃的。
在路径上点p之前T1或T2没有被求值,则编译器可以忽略这个冲突。4
- 4
一个不存放值的临时变量可以和任何其它临时变量共享一个寄存器。我们可以将其它临时变量中的值赋给它,因为它有什么样的值是无所谓的。
证明(Proof)
给定一个路径,沿着路径向着入口方向向后行走。在开始行走时,T1和T2都是活跃的。当其中之一变为不活跃的第一条指令处停下来。下面是几种可能:
没有指令变为不活跃。这种情况下,在p之前的路径上,没有指令对临时变量求值,因此它们都包含未初始化的数据,于是出现上面的第三种情况。
其中一个临时变量变为不活跃,因为它是一条指令的目标。由于我们在临时变量变为不活跃的第一条指令处停下来,另一个临时变量还是活跃的,因此这是前面两种情况的其中之一。
其中一个临时变量变为不活跃,因为从入口点到当前点的任意路径上,没有对这个临时变量求值。这种情况下,此路径没有对这个临时变量求值,因此这是第三种情况。
根据活跃和不活跃的定义,只会出现这些情况,因此我们证明了这个观察结论。
这个观察意味着,我们不必为在一个点活跃的每一对临时变量创建冲突。编译器只需要在它们之间创建冲突,就是在一个点被求值的临时变量和在这个点活跃的其它临时变量。这得出了图11.11中的算法。它按照活跃/死亡分析一样的方法,为节点中的临时变量计算生命期信息,然后利用这些信息和最后的观察将冲突添加到冲突图中。
<Figure 11.11 Computing a Partial Conflict Graph>
作为一个例子,考虑图11.12中的直线型代码片段。假设T5是代码结尾处唯一活跃的寄存器,T0和T2是代码开始处活跃的寄存器。向后扫描指令,我们得到图中第二列列出的冲突,这些是由指令建立的冲突。
在编译器中有两个地方会用到这个算法。首先,寄存器重命名和寄存器合并算法会用到它。为了那个目的,它需要作如下描述的修改。之后,全局寄存器分配会按这里陈述的样子使用它。
在寄存器重命名和寄存器合并期间,编译器计算临时变量的一个划分:当流图被翻译回正常形式的时候,属于相同划分的两个临时变量将被赋予相同的名字。编译器需要两个划分之间的冲突的概念:两个划分是冲突的,如果存在任意的点,在那个点两个划分都有元素是活跃的,并且无法知道它们存放相同的值。话句话说,一个划分在它的元素活跃的点的交集上是活跃的。构建划分的冲突图的算法和临时变量的是一样的;然而,边是在(FIND(T1), FIND(T2))之间构造的,而不是在(T1, T2)之间,其中划分是由UNION/FIND算法表示的。
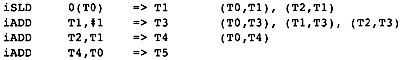
图11.12 Example Conflict Graph
11.4 结合的寄存器重命名和寄存器合并
限制资源phase为寄存器重命名、窥孔优化和部分寄存器合并实现了一个结合的算法。结合是基于这样的观察的,就是这些算法都计算临时变量的一个划分,在翻译回正常形式期间使用这个划分。起初建立静态单赋值形式超出了寄存器重命名的要求;它指派太多的新寄存器名字,插入复制操作在它们之间复制值。寄存器重命名创建最小的划分,删除所有这些插入的复制操作。不是直接删除它们,而是将它和寄存器合并中的删除复制操作相结合。
11.4.1 寄存器重命名
寄存器重命名消除这样的情形,就是流图的不同部分使用了相同的临时变量来存放不同的值。静态单赋值形式为寄存器重命名提供了一个基础。回想,静态单赋值形式为值的每次定义生成一个新的临时变量名字。当翻译回正常形式时,这些名字被重新结合来消除由ϕ节点隐含的复制操作。回想,翻译回正常形式是由临时变量之间的关系控制的。在正常形式的流图中,两个相关的临时变量共享相同的名字。
在实现寄存器重命名的时候,构建消除所有来自ϕ节点的复制的最小关系。这个关系是一个条件的传递闭包,这个条件就是,两个临时变量是相关的,如果一个是ϕ节点的操作数,另一个是相同ϕ节点的目标。关系是这样实现的,就是利用UNION/FIND算法创建所有临时变量的一个划分。因此,算法包括翻译为最小的SSA形式,通过声明每个ϕ节点的操作数和目标是相关的来构建划分,还有翻译回正常的形式。
11.4.2 寄存器合并
寄存器合并删除尽可能多的复制操作。很多复制操作已经在窥孔优化期间被删除了,所有复制操作,除了ϕ节点隐含的和涉及非正常边上关联ϕ节点的临时变量的复制操作,都被它删除了。最大比例的复制操作是这样被删除的。对于剩余的复制操作,利用Chaitin(1981)的观察删除它们:如果一个复制操作的源和目标不相冲突,那么它们可以结合为一个寄存器。一旦两个临时变量被结合了,此算法可再次应用于另一个复制操作。此观察创建了临时变量的一个划分:如果两个临时变量在寄存器合并期间被结合了,它们就属于相同的分组。
SSA形式的寄存器重命名算法会在流图中生成非正常边关联的ϕ节点。当流图被翻译回正常形式时,必须不让这些ϕ节点生成复制操作。因此,算法必须避免删除那些会导致复制操作出现在非正常边上的复制操作。照常来说,非可能边是没关系的,因为反正其上的代码绝不会被执行。
此算法包括利用SSA形式消除大部分复制操作。初始地,这样划分临时变量,每个临时变量自身构成一个分组。然后,调查每个ϕ节点和复制指令。如果一个操作数和目标临时变量不相冲突,就把它们放入相同的分组。然后,将流图翻译回正常形式。
注意寄存器合并和寄存器重命名之间的相似性。它们都创建了一个划分,用来消除ϕ节点处的复制操作。
11.4.3 集成算法
集成寄存器重命名和寄存器合并是简单明了的。它们都建立临时变量的一个划分,为了重构流图的正常形式。寄存器合并建立最小的划分,寄存器重命名会无偿发生。
驱动程序如图11.13所示。流图已经是静态单赋值形式。首先,计算全局值编码,这样编译器就知道哪些临时变量可能具有相同的值:这用来计算冲突图。初始地,每个临时变量自身被放入划分的一个单独分组。然后,对于一对临时变量,如果它们出现在非正常边上的复制操作中,就合并它们的分组,这样就不会出现涉及它们的复制操作。我们已经约束了窥孔优化,因此这是合法的。
<Figure 11.13 Coalescing and Renaming>
现在利用Chaitin的观察合并划分集合,这和这样的重命名是一样的,就是重命名一个临时变量,让它和另一个临时变量一样。利用一个UNION/FIND算法实现划分,划分中分组的FIND用作临时变量代表。如果两个临时变量不相冲突,就可以合并为一个。在这个点,编译器只关系合并那些作为复制操作或ϕ节点的源和目标的临时变量。之后在全局变量分配期间,会利用相同的观察来分配寄存器。
在研究COALESCE_TEMPORARIES的时候,我们会发现,当我们合并两个临时变量时,需要更新冲突图。然而,更新是保守的,是不精确的,因此重新计算冲突图并重复合并,直到没有更多的复制操作可消除。
图11.14中的COALESCE_TEMPORARIES遍历流图,检查所有复制操作。如上所述,存在两种形式的复制:来自中间表示的显式复制和ϕ节点中的隐式复制。鉴于一些复制的删除可能会阻碍另一些复制的删除,遍历流图的时候,首先处理执行最频繁的block。如果不能通过统计或静态估计获得此信息,就先处理循环最里面的block。这个信息也没有,就按任意次序遍历block。

图11.14 Walking the Graph and Checking Coalescing
最后,图11.15中的CHECK_COALESCE作真正的事情。分组的冲突信息存储为临时变量代表的冲突信息,因此首先找出临时变量代表。如果它们是相同的代表,那么临时变量已经被直接或间接地合并了。其次,检查它们是否冲突。如果是冲突的,就不做什么;否则,用UNION方法合并这两个分组,将原来分组的冲突信息的联合赋予新的临时变量代表。

图11.15 Coalescing Two Temporaries
UNION/FIND算法正常的实现让T0或T1作为新的临时变量代表。?这样的话,其中一个循环可以省去。在这个pass中,一旦消除了一个复制操作,就标记发生改变了。如果余下没有复制操作了,算法也可以停止。
这项技术的优势是什么?如早前所述,局部合并消除大部分复制操作,而不使用冲突图。其次,全局值编码允许消除级联的复制,而不用重复创建冲突图。第三,算法只为那些有机会合并的临时变量计算冲突图。
有些其它目标架构要求一种隐含的合并。如果目标机器不是RISC处理器,那么它可能有这样的指令,指令结果被存放到一个操作数中。中间表示模仿了RISC处理器,寄存器分配器希望让尽可能多的目标和操作数之一相同。为此,用两条目标机器指令替换一条RISC指令:从一个操作数到目标的复制指令和具有相同目标和(隐含)操作数的目标机器指令。利用合并消除这个复制指令,也就是说,让操作数和目标为相同的临时变量。
11.5 计算寄存器压力
编译器已经尽可能地减小了在用临时变量的数目。现在编译器需要决定每个临时变量在流图中什么地方被赋予寄存器。无论何时一个临时变量在使用中,它是在寄存器中;但是,在使用之间,它可能被挤出(spill)到临时内存位置。我们把所需寄存器数目的粗略估算称作寄存器压力(register pressure),所以编译器必须首先计算寄存器压力或者每个点活跃寄存器的数目。如果有多个寄存器集,例如不同的整数和浮点数寄存器,那么单独为每个寄存器集计算寄存器压力。
定义
寄存器压力 :给定流图中的一个点p,寄存器压力是在p处活跃临时变量的数目。如果有分开的寄存器集,那么每个集的寄存器压力是单独计算的。
通过计算每个block末尾活跃的临时变量集合,可以确定寄存器压力。这个集合的尺寸给出了block中最后一条指令后面的寄存器压力。然后,编译器向后遍历每个block,追踪每个点哪些寄存器是活跃的。集合的尺寸就是寄存器压力。在每条指令处,编译器将执行下面的步骤:
首先,对于一条指令,将存放其(结果)值的临时变量标记为不活跃,并将它移出活跃寄存器集合。如果这个临时变量在此之前是不活跃的,那么可以删除这条指令。
接着,将作为指令操作数的临时变量标记为活跃。
该指令之前的寄存器压力是处理该指令之后活跃寄存器集合的尺寸。记住,我们按照逆向执行顺序处理指令。
除了每条指令处的寄存器压力,算法需要知道每个block和每个循环的最大寄存器压力。为此,编译器利用循环树(loop tree)。一次遍历这棵循环树就可以计算得到所有关于寄存器压力的信息,如图11.16所描述那样。
寄存器压力是循环树的一个综合属性。其中每个节点的寄存器压力,是其子节点的寄存器压力的最大值。因此,计算一个循环的寄存器压力,就是找出封闭的循环和block的最大寄存器压力,如图11.17所示。

图11.16 Finding Register Pressure In Flow Graph

图11.17 Finding Pressure in a Loop
计算一个block的寄存器压力如图11.18所示。这个结构模仿了活跃/死亡分析所采用的计算局部生命期信息的方法。按照逆向执行顺序扫描block,按照向后的顺序执行每条指令。当发现一个定义时,其临时变量变为不活跃;当发现一个使用时,其临时变量变为活跃,除非它已经是活跃的。寄存器压力是每对指令之间活跃寄存器的数目。
<Figure 11.18 Computing Pressure in a Block>
有些处理器,例如INTEL i860,包含这样的指令,它们在使用操作数之前定义目标寄存器。在这种情况下,必须改变代码以符合硬件的要求。对于这些特定的指令,会按照向后执行顺序,首先引用其操作数,然后修改其目标。
11.6 减小寄存器压力
现在,编译器将通过减小流图中每个点的寄存器压力,使它不大于可用的物理寄存器数目,来简化寄存器分配问题。如果存在多个寄存器集,则单独处理每个集。编译器找出寄存器压力太大的点。它将一个临时变量在这个点之前存储到内存,又将它在这个点之后加载回来。每次使用临时变量,它必须在寄存器中。在存储它的STORE和加载它的LOAD指令之间,这个临时变量不再活跃,于是寄存器压力减小了。
归纳起来说,假设流图中点p处的寄存器压力太高了,一个临时变量T将被挤出(spill)到内存。必须指派一个内存位置MEMORY(T)存放T的值。然后,必须向程序添加指令在T和内存位置之间搬运数据。如果T在程序中点p处是活跃的,而编译器想在那个点再利用存放T的寄存器,那么
在T被求值处到p的每条路径上,插入store操作,将数据从T搬到MEMORY(T)。
在p到可能把T用作操作数的任何指令处的每条路径上,插入load操作,将数据从MEMORY(T)搬到T。
满足这些条件并不难。编译器可以在每条计算T值的指令之后插入一条store操作,在每条使用T值的指令之前插入一条load操作。问题在于,这会生成太多内存引用指令。在现代处理器上,内存引用是最昂贵的操作之一,因此编译器要减小这类指令的数目。这些指令还消耗指令缓存空间,进一步降低性能。
如果程序中存在一个点,其寄存器压力超过可用寄存器的数目,那么编译器会挤出(spill)一个临时变量以减小寄存器压力。5 因为编译器想要减小被执行的load和store操作的数目,它从程序中执行频度最高的点开始作临时变量挤出,尝试在执行频度较小的点插入load和store操作。为此,在函数中寄存器压力最大的点执行三个步骤:
- 5
存在这样的情形,寄存器压力不是所需寄存器数目的准确度量。有时候,需要更多的寄存器,由于复杂交织的寄存器使用模式。有些穿过流图的路径不会被执行,有的点存在未初始化临时变量,这些地方所需的寄存器可能较少。然而,通常寄存器压力非常接近所需的寄存器数目。
找出包含p的最大循环(最外层循环),在p处存在一些这样的临时变量T,它们跨越循环是活跃的,在循环中没有被使用。T中存放的值向下传递,穿过循环。在循环开始处,插入一个store操作,把T存储到MEMORY(T),在T活跃的每个循环出口处,插入一个load操作,从MEMORY(T)载入T。尝试最大限度向函数入口处移动store操作,而不增加它们被执行的次数。尝试最大限度向函数出口处移动load操作,而不增加它们被执行的次数。这可能减小其它点的寄存器压力。
如果找不到这样的循环和临时变量T,就想办法处理寄存器压力太高的单个block。找出一个这样的临时变量T,它在整个block是活跃的,在block中没有被使用。如果T在block后面是活跃的,就在block之前插入store操作,在block之后插入load操作。同样地,尝试向函数入口block移动store操作,向出口block移动load操作。
如果以上方法都无法减小寄存器压力,就得在寄存器压力太高得block内部插入load和store操作。选择这样一个临时变量T,它在点p处是活跃的,此点之后的大量指令没有使用它。在T的定义之后(或者在block的开始处,如果它在block内没有定义的话),插入一个store操作。在T的下一次使用之前(或者在block的末尾,如果它在block内没有被使用的话),插入一个load操作。如果load出现在block的开始处,就尝试最大限度让它远离函数入口,而不增加执行的频度。类似地,最大限度让store远离函数出口。
一旦编译器插入了load和store操作,它就利用部分冗余消除技术让load远离入口block,让store远离出口block。利用EARLIEST算法,尽可能远地移动这些操作。
记得寄存器分配是NP-完全问题,因此不存在一个对所有情形都表现良好的算法。这意味着,实现者(和作者)必须拒绝太复杂的分配机制:过去的经验表明,它们给不了对等的回报。
这样做更有效率,就是为每个循环计算可以挤出(spill)的临时变量,然后扫描各个循环,从外层到内层,如果寄存器压力太高,就挤出(spill)临时变量。为流图中的每个循环和block计算一个属性,Through(L)。图11.19和11.20给出了算法。
函数COMPUTE_THROUGH开始递归遍历循环树。只有那些寄存器压力高的循环才需要它,因而不用为不太复杂的循环计算这个属性。这会节省一点时间。注意,对于包含其它循环的循环,这不成立。如果外层循环具有高的寄存器压力,那么即使内层循环不太复杂,也会计算它的寄存器压力。避免不需要的计算让事情变得太复杂。
函数COMPUTE_THROUGH_LOOP单独处理来自循环的block。对于一个block,一个临时变量在整个block是活跃的,在block中没有引用,当且仅当它在block的开始处是活跃的且没有引用。警告:如果一个临时变量在block的开头和末尾都是活跃的,则未必它在整个block是活跃的,因为它可能在block中变为不活跃,后来再变为活跃。当然,如果临时变量在block中没有引用,就不会发生这种情况。

图11.19 Computing Transparent Temporaries

图11.20 Main Through Calculation
那些在整个循环中活跃而没有引用的临时变量的集合,是循环的每个组件的相应集合的交集。函数COMPUTE_THROUGH_LOOP计算这个交集。编译器只关注最外层循环,在其中一个临时变量是活跃的而没有引用,因此计算循环的Through集合之后,它删除内层循环中对这些临时变量的引用。
对于单入口循环,计算Through属性有更简单的办法。对于单入口循环,一个临时变量在整个循环中活跃而没有引用,当且仅当它在入口block的开头是活跃的且在循环中没有引用。这是成立的,因为在循环中从一个block到其它block都有一条路径。对于多入口循环,这是不成立的,因为编译器在循环的开始处添加了若干block,创建流图的单入口区域。在这些添加的block中,从一个block到其它block不存在路径。
11.7 计算寄存器Spill点
算法是这样被描述的,编译器找到一个寄存器压力太高的点,又找到一个跨越循环占用寄存器的临时变量,挤出(spill)这个临时变量。向下遍历循环树是一个更简单的方法。考虑每个循环的寄存器压力。如果压力太高,就挤出一个这样的临时变量,它在整个循环是活跃的,在循环中没有被引用。一直这样做,直到寄存器压力降低了。
这可能是无效率的,因为算法在一个循环中选择一个临时变量并挤出它,在另一个循环中选择不同的临时变量并挤出它;这样,可能会在两个循环之间插入大量的load和store操作,尽管可以为两个循环挤出一组临时变量,避免在它们之间插入load和store。编译器尝试这样避免这个问题,就是基于一个循环的所有子循环选择挤出的临时变量。这只是一个启发式方法,因为选择挤出哪些临时变量,获得最优的方案,是一个NP-完全问题。
在图11.21中,算法以驱动函数开始,它只计算寄存器压力和包含如此临时变量的Through集合,这些临时变量在每个循环中是活跃的,但是没有被引用。然后这个函数开始遍历循环树。当函数遇到压力小于寄存器数目的block或节点时,停止遍历。最终,它为指令调度重新计算压力。
这个算法有两个基本的函数:一个减小循环中的压力(见图11.22),另一个利用一个不同的算法减小block中的压力(稍后在小节11.7.1中描述)。我们已经讨论了在循环中减小压力的算法。减小block内的压力是最后的措施, 只有不存在如此临时变量时才会被执行,它们在整个block活跃并且没有被使用。
现在,我们来讨论减小循环中的压力,如图11.22描述的那样。算法的描述比实际想法更胆怯。计算循环或block的集合,High_Pressure,它们内部的寄存器压力太高。编译器要挤出一个在这些循环中都活跃的临时变量,如果可能的话。到最后,计算一个优先级队列,Excess_Pressure,由High_Pressure所包含的循环或block组成。优先级由寄存器压力的超额给定。算法选择一个待挤出的临时变量(很快会描述),然后挤出它(很快也会描述)。当在循环中挤出了尽可能多的临时变量,如果必要的话,才在子循环和block中挤出临时变量。

图11.21 Driver for Reducing the Pressure

图11.22 Spilling Temporaries in a Loop
怎么选择待挤出的临时变量呢?考虑图11.23中的算法。选择压力超额最多的循环(或block)。这个循环的Through集合中的每个临时变量都是挤出候选者。被选的临时变量也是大多数其它需要挤出临时变量的循环的挤出候选者。这让优化安置load和store操作的算法获得最大的机会来避免一些load和store操作。
图11.24中的算法描述了如何插入load和store操作。首先,必须有一个内存位置存放这个值。所有对相同临时变量的引用必须使用相同的内存位置。在循环入口之前插入store操作,如果临时变量在循环出口点仍然活跃,就在那里插入load操作。循环内部没有引用这个临时变量,这保证了新程序和原始程序具有完全相同的计算效果。然后更新数据结构。如果循环不再有超限的寄存器压力,就把它移出Excess_Pressure和High_Pressure。如果它仍然有超限的寄存器压力,那么优先级减一。

图11.23 Choosing which Loop Temporary to Spill

图11.24 Inserting Spilled Loads and Stores

图11.25 Updating Pressure
更新寄存器压力是代价最高的动作,因此编译器采用近似的办法减小预先选择的循环和block的压力。优化安置load和store操作的算法可能在其它地方减小压力。然而,在一个循环内的很多必要的地方挤出相同的临时变量,让近似方法表现更好。所有这样的循环和block确实挤出了临时变量,调整了压力,原来它们的压力是高的,并且有临时变量可以被挤出。那些压力不太高的循环或者block,其压力得不到调整。因此,算法会遍历循环树,所记录的压力减一。当到达压力低的叶子或循环时,就停下来。在图11.25中,算法被描述为简单地向下遍历这棵树,修正属性Pressure的值。
11.7.1 减小block的压力
在单pass寄存器分配中,经典的spilling算法被用来在block中挤出(spill)临时变量。按照执行顺序扫描整个block。当到达寄存器压力太高的点时,选择一个这样的临时变量,它在这个点是活跃的(因此压力将会减小),并且将来它下次被用作一个指令的操作数的位置是最远的。挤出这个临时变量将最大化block的指令序列,那里的压力减小了。为了选择这个临时变量,如果一个活跃的临时变量在这个block中不再被使用,就假设它在block末尾后面有虚假的使用。
这个算法实现为两个pass。第一个pass向后扫描整个block,组建一列这样的指令,它们使用了出现在这个block中的每个临时变量,然后计算每条指令之前的寄存器压力(图11.26)。它模仿我们之前用来计算活跃/死亡信息和寄存器压力的代码。注意,寄存器合并和寄存器重命名保证了在block中一个临时变量只有一次求值。因此,这列指令的开始时一个临时变量变为活跃的第一个点。
第二个pass向前扫描整个block(图11.27)。经过每条指令的时候,将它移出之前组建的列表,使得列表总是存放block中余下的临时变量引用。在向前扫描的过程中,维护一个所有活跃临时变量的集合。当寄存器压力超过寄存器数目时,其中一个临时变量被存储到内存,在下次使用之处把它加载回来。为了在block的开始处跟踪活跃临时变量的集合,利用了起始pass计算的Live集合,随着编译器向前扫描整个block,对临时变量执行反向动作。

图11.26 List of Uses for Reducing Pressure

图11.27 Reducing Pressure in a Block
应该存储哪个临时变量呢?那个将来下一次使用位置最远的临时变量。换句话说,扫描活跃临时变量集合,选择其使用列表的下一个条目最近的一个临时变量。这是单pass寄存器分配器使用的经典启发式方法,它尽可能让一个寄存器保持长时间可用。
在指令中实际的寄存器压力太高的点,是在使用操作数(这可能减小寄存器压力)和目标写入值(这可能增加寄存器压力)之间。如果压力太高,就在这条指令之前存储待挤出(spill)的临时变量(临时变量必须是该指令的一个操作数,或者是该指令没有用到而活跃的另一个临时变量)。下次使用之前,必须再次加载这个值。如果临时变量是活跃的,而block不再使用它,就在临时变量活跃的每个出口插入load操作,并调用优化安置挤出操作的算法。类似地,如果在block的开始处插入load操作,就必须调用优化算法来改善挤出操作的位置(见图11.28)。

图11.28 Inserting a Spill within a Block
11.8 优化Spill指令的位置
一旦存储和载入操作的初始位置确定之后,编译器着手优化这些STORE和LOAD指令的位置,把它们移动到执行频度较低的点。移动它们的动作减小了所越过点的寄存器压力,让压力减小算法的后程变得容易。
为了优化安置这些存储和载入操作,编译器为每个挤出(spill)的临时变量建立下面的集合。需要在整个挤出过程和整个流图中维护这些集合,因为在流图的一个区域挤出一个临时变量,可能会改变流图其它部分的存储和载入操作的位置。
STORE_IN(T)是在block的开头有STORE指令的block的集合,指令将T存储到MEMORY(T)。
STORE_OUT(T)是在block的末尾有STORE指令的block的集合,指令将T存储到MEMORY(T)。
LOAD_IN(T)是在block开头有LOAD指令的block的集合,指令从MEMORY(T)载入T。
LOAD_OUT(T)是在block末尾有LOAD指令的block的集合,指令从MEMORY(T)载入T。
这节描述改善安置这些载入和存储操作的算法。一旦基于循环的算法确定了循环外部指令的位置,编译器就为这些载入和存储操作连同之前相同临时变量的载入和存储操作寻找更好的位置。所用的算法是部分冗余删除的EARLIEST算法。
11.8.1 优化Store操作
考虑将T挤出到MEMORY(T)的存储操作。这些指令只依赖T,可视为一元(unary)操作。我们一旦定义了评估存储操作意味什么,定义了什么操作会杀死它们,就可以像任何其它指令那样优化它们。(注:杀死的含义是让它失效。)
什么指令会评估存储操作?它们是那些保证其执行之后内存中的值和T中的值是一样的指令。显然,编译器插入的存储操作满足这个条件。然而,从MEMORY(T)到T的载入操作也满足这个条件。因此,评估存储操作的指令包括存储和载入指令。
什么指令会杀死存储操作?它们是破坏如此条件的指令,这个条件是T中的值和MEMORY(T)中的值一样,它们是修改T的任何指令。注意,LOAD指令首先杀死T,然后产生评估存储操作的效果。
注意,T被用作操作数不影响存储操作的安置。向入口block移动存储操作,它们永远不会改变T的值,因此一个存储操作可以越过T的使用,而不影响任何寄存器的值。这样我们得到了预期和可用的如下定义:
STORE_ANTLOC(I) = STORE_IN(T)
STORE_AVLOC(I) = STORE_OUT(T) ∪ LOAD_OUT(T)
STORE_TRANSP(B) = {T | B中的指令不修改T}
现在,可以用这些集合计算STORE_ANTIN、STORE_ANTOUT、STORE_AVIN和STORE_AVOUT。然后,可以用EARLIEST方程计算STORE_EARLIEST。这指示了在哪些点插入新的STORE指令,在哪些点删除旧的STORE指令的实例。
相比表达式全局优化的情形,STORE指令应该尽可能向远处移动。这可能减小流图其它部分的寄存器压力,避免否则发现不了的进一步挤出(spill)。因此,使用了EARLIEST算法,而不是LATEST算法。
STORE_EARLIEST的计算利用了EARLIEST方程,将存储操作的预期集合和可用集合替换为这里描述的相应集合。插入和删除STORE指令的算法还用到了EARLIEST中描述插入和删除的方程。
需要进一步优化以减小流图中存储操作的数目。EARLIEST方程可以描述在所有通向一个block的边上插入相同的计算。这时,应该在block的开头插入计算,而不是一条边上。还有,如果算法描述了在同一个block的开头插入又删除一个存储操作,就不要插入或删除。当不能移动一个存储操作时,EARLIEST会发生这种情况:算法描述了在通向block的每条边上插入一个存储操作,又在block中删除它。
在这个算法中,非正常边遇到了和部分冗余相同的问题,而解决方法是一样的。如果算法试图在非正常边上插入一个存储操作,编译器就假装在边的开头有一条修改T的指令。这样,T不是预期的,在边上不会发生插入。添加了这条指令之后,再次执行算法,计算在哪些点插入存储操作,得到这些点的新的集合。图11.29描述了完整的算法。
11.8.2 优化LOAD的位置
可用相同的技术移动载入操作,除了编译器需要向出口方向移动它们。我们在反向图上沿着前驱节点应用部分冗余算法,类似正常的EARLIEST算法沿着后继节点遍历正向图。
为此,编译器必须知道哪些指令评估一条LOAD指令,哪些指令杀死它。一条指令评估一条LOAD指令,如果它保证临时变量中的值和内存中的值相同。明显地,一个LOAD指令评估一个LOAD指令,一个STORE指令也评估一个LOAD指令。

图11.29 Inserting and Deleting Spilled STOREs
哪些指令杀死一个LOAD指令?临时变量的一次使用或求值杀死一个LOAD指令。使用会杀死它,因为越过这个使用移动LOAD将破坏这个使用的值。临时变量的求值会杀死它,因为它会生成一个值,它不同于内存中的值。
到出口的一些路径可能不再使用临时变量T,这时可以进一步优化。如果在插入LOAD指令的点T不活跃,就可以取消这次插入。
11.9 参考文献
Chaitin, G. J., et al. 1981. Register allocation via coloring. Computer Languages 6(1):47-57.
Leverett, B. W., et al. 1979. An overview of the Production-Quality Compiler-Compiler project. (Technical Report CMU-CS-79-105.) Pittsburgh, PA: Carnegie Mellon University.